这是一篇关于一道算法课课后作业解题过程的一些思考
最近开始上算法设计与分析课,课后老师布置了一道关于时间复杂度的编程题。题目应该是老师自己编的。说实话,时间复杂度这种东西以前从来没有重视过,只停留根据代码判断程序时间复杂度的阶段。所以一开始也觉得做这种题目真是浪费时间(当然现在好像也觉得这题目没什么卵用
题目如下:
为了简单,只考虑6种算法的时间复杂度类型,分别为O(n),O(nlogn),O(n^2),O(n^3),O(2^n)和O(n!)。现有大量运行结果,请你根据运行结果判断复杂度类型。
输入:
第一行:一个整数k,表明有k对运行数据(n, t),n为运行规模,t为运行时间,都是整数。
第二行:k个整数,为运行规模,整数(<1000001),每个数据之间有一个空格
第三行:k个整数,为运行时间,整数(<100000),每个数据之间有一个空格
重复这三行,直至k=0。
输出:
每个例子输出一个整数(1-6之间),占一行,1,2,3,4,5,6分别代表复杂度类型O(n),O(nlogn),O(n^2),O(n^3),O(2^n)和O(n!)。最后一个例子也有回车
输入实例:
4
8 10 11 9
0 375 4218 31
6
17 20 24 19 22 25
16 110 1703 47 406 3468
5
359999 431998 518397 300000 746491
31 47 47 31 78
0
输出示例:
6
5
2
思考
探索一:
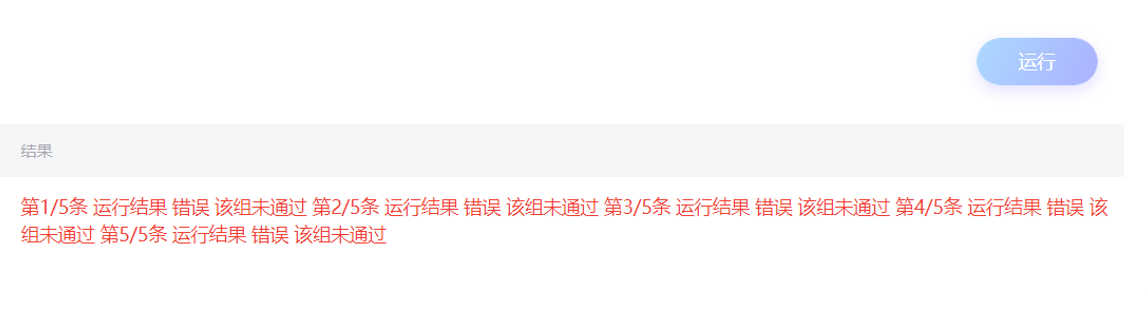
第一眼看到题目的时候一边想着这什么鬼一边又觉得这题目还挺新颖的。首先想到的是从运行规模之间的差值和运行时间的比值这方面下手。感觉这也是很多同学一开始的思路,然后做着做着发现这样的做法好像不需要用到k组数据呀,不是两组就行了吗。不管了,先做下去吧。代码写完,用实例测一遍,emmmmmm… 没过,不管先去页面上run一次。好家伙,一组数据都没通过。
![https://cdn.jsdelivr.net/gh/xxy-im/storage@gh-pages/images/run_complexity2.png]() 提交运行
提交运行
探索二:
我真的太菜了,实在不行我做下假输出骗个分得了,老师应该不会查代码吧。说干就干……
What the FXXK!
![https://cdn.jsdelivr.net/gh/xxy-im/storage@gh-pages/images/run_complexity1.png]() 假输出测试
玩我呢,123456都试过了,就这就这?记得班群里有个同学过了一组数据,问他要了下他的代码,然后把他的输出分别写死123456,一样全都过不了。好吧,是后台有什么判断机制?
假输出测试
玩我呢,123456都试过了,就这就这?记得班群里有个同学过了一组数据,问他要了下他的代码,然后把他的输出分别写死123456,一样全都过不了。好吧,是后台有什么判断机制?
探索三:
取不了巧,只好老老实实coding了,又做了两三种基于探索一的变种算法,样例数据都最多只能过两组,提交运行依然是没有一组通过。真的生气了,总觉得是后台有问题。喝了瓶薄荷味苏打水冷静了会儿后,决定还是从探索一的方法种的根本问题着手,即使用k组数据的问题,上面说了探索一中是基于两组数据的差值或比值分析,根本没完全利用到k组数据。既然要用k组数据,那我们先把一组数据单独拎出来研究好了。
当我们知道一个程序的运行规模n,和程序运行时间,那我们是不是能得到它的单位运行时间(不知道这个说法对不对,可以理解为当n为1的运行时间)。当然不能单纯的t / n,应该用t去除以n对应的复杂度函数才行,当每组数据按照某个复杂度函数除出来的单位时间最相近就是它对应的复杂度。 单位运行时间我就用uTime表示吧。
用示例中的数据举例:
第一组数据: n = 8, t = 0;
- 按
O(n)求uTime: t / n;
- 按
O(nlogn)求uTime: t / (n*log(n));
- 按
O(n^2)求uTime: t / (n*n);
- 按
O(n^3)求uTime: t / (n*n*n);
- 按
O(2^n)求uTime: t / (pow(2, n));
- 按
O(n!)求uTime: t / n!;
输入的k组数据都按照这个算法求得uTime,然后比较6种复杂度对应的k个uTime,当k个uTime最接近时候对应的复杂度算法便是该输入对应的复杂度。这里我用的方差去算的k个uTime的接近程度。当然这里的方差算法被我改动了,因为不同算法输入的规模n的数量级相差太大了,所以算方差的时候做了一个类似Normalization的方法。
方差计算代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
// 计算方差
double Variance(vector<double> &uTimes)
{
double sum = std::accumulate(std::begin(uTimes), std::end(uTimes), 0.0);
double mean = sum / uTimes.size(); //均值
double accum = 0.0;
std::for_each (std::begin(uTimes), std::end(uTimes), [&](const double d) {
accum += (d/mean-1)*(d/mean-1); // Normalization,不然不能相互比较
});
return sqrt(accum/(uTimes.size()));
}
|
AC
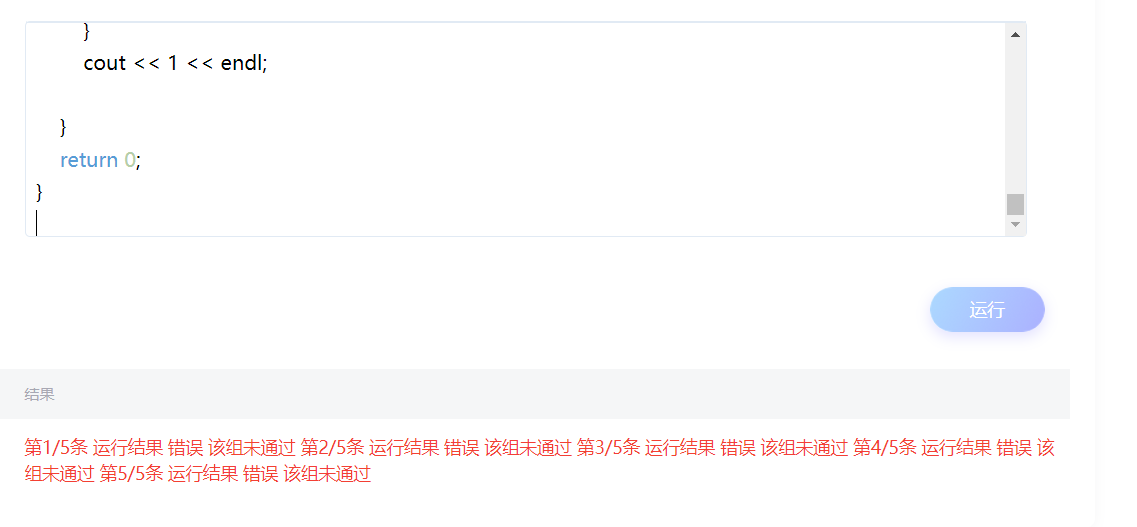
感觉探索三的思路没大问题了,但有一点,就是在n的数量级太大的时候2^n和n!根本没法算,所以示例数据前两个都是过了,第三个会崩。然后我又是先不管这个问题了,草草的把代码先写出来后就迫不及待的提交运行了。
!!!又是一组都没通过!!!
简直要爆粗口了,真的有理由怀疑后台有问题。反复的做实验,监视各个阶段的输出,觉得一切的很合理,但结果为什么就这么不合理呢。实在不知道怎么做了,就想着把O(2^n)和O(n!)的大规模输入问题先解决掉。这时想到了上一个作业,老师让我们编程输出这6个复杂度1s内能处理的最大规模N,O(2^n)和O(n!)在1s内能处理的问题规模都是很小的,都是两位数的数量级。于是我便想到一个trick,当n > 30时,则不计算O(2^n)对应的uTime,同时把其对应的方差设成一个很大的值,例如10000这样。同理当n > 30时,O(n!)对应的操作也做同样处理。
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
int GetComplexity(map<int, int> &nt)
{
vector<double> uTimes; // 记录不同复杂度对应的单位运行时间
vector<double> vars; // 记录6种复杂度对应uTime的方差
for (int i = 0; i < 6; i++)
{
uTimes.clear();
bool flag = false;
for (auto ntIter = nt.begin(); ntIter != nt.end(); ntIter++)
{
auto n = ntIter->first;
auto t = ntIter->second;
if ( i > 3 && n > 30)
{
flag = false;
break;
}
uTimes.push_back(Fun[i](t, n));
}
vars.push_back(!flag ? Variance(uTimes) : 10000);
}
auto min = min_element(begin(vars), end(vars));
return distance(begin(vars), min) + 1; // 返回最小方差的索引+1
}
|
为了方便实现探索一中的算法,所以用的std::map存储(n, t),因为它能根据键值自动排序。后面也没有改过来,其实只用两个std::vector就可以了。 处理完后,我再提交,竟然就过了…就过了…过了…了…, 所以前面显示的未通过到底是什么? 是程序中断了吗? 还是什么神秘的控制机制。
![https://cdn.jsdelivr.net/gh/xxy-im/storage@gh-pages/images/ac.png]() 喜大普奔
喜大普奔
完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
|
/*
* @Author: xxy
* @Date: 2021-09-16 16:41:37
* @Description: 复杂度判断
*/
#include <iostream>
#include <vector>
#include <map>
#include <cmath>
#include <numeric>
#include <algorithm>
using namespace std;
// 求阶乘
int Fn(int n)
{
int f;
if (n == 0 || n == 1)
f = 1;
else
f = Fn(n - 1) * n;
return f;
}
// 计算方差
double Variance(vector<double> &uTimes)
{
double sum = accumulate(begin(uTimes), end(uTimes), 0.0);
double mean = sum / uTimes.size(); //均值
double accum = 0.0;
for_each (begin(uTimes), end(uTimes), [&](const double d) {
accum += (d/mean-1)*(d/mean-1); // Normalization,不然不能相互比较
});
return sqrt(accum/(uTimes.size()));
}
// 求单位运行时间
double f0 (double t, int n) { return t / n; } // O(n)
double f1 (double t, int n) { return (t / (n * log2(n))); } // O(nlogn)
double f2 (double t, int n) { return (t / pow(n, 2)); } // O(n^2)
double f3 (double t, int n) { return (t / pow(n, 3)); } // O(n^3)
double f4 (double t, int n) { return (t / pow(2, n)); } // O(2^n)
double f5 (double t, int n) { return (t / Fn(n)); } // O(n!)
// 定义函数数组
double (*Fun[])(double t, int n) { f0, f1, f2, f3, f4, f5 };
int GetComplexity(map<int, int> &nt)
{
vector<double> uTimes; // 记录不同复杂度对应的单位运行时间
vector<double> vars; // 记录6种复杂度对应uTime的方差
for (int i = 0; i < 6; i++)
{
uTimes.clear();
bool flag = false;
for (auto ntIter = nt.begin(); ntIter != nt.end(); ntIter++)
{
auto n = ntIter->first;
auto t = ntIter->second;
if ( i > 3 && n > 30)
{
flag = false;
break;
}
uTimes.push_back(Fun[i](t, n));
}
vars.push_back(!flag ? Variance(uTimes) : 10000);
}
auto min = min_element(begin(vars), end(vars));
return distance(begin(vars), min) + 1; // 返回最小方差的索引+1
}
int main()
{
int k;
int tmp;
map<int, int> ntMap;
while (cin >> k && k)
{
vector<int> nVec;
vector<int> tVec;
ntMap.clear();
for (int i = 0; i < k; i++)
{
cin >> tmp;
nVec.push_back(tmp);
}
for (int i = 0; i < k; i++)
{
cin >> tmp;
tVec.push_back(tmp);
}
for (int i = 0; i < k; i++)
{
ntMap[nVec[i]] = tVec[i];
}
cout << GetComplexity(ntMap) << endl;
}
return 0;
}
|
小结
题目做完了,好像学到了点什么,又好像什么都没学到。总觉得这道题目但凡有一点意义也不至于一点意义也没有。